The use case
I wanted a way to quickly screencap good and bad examples of fancy web graphics. However, using wget doesn’t work because wget won’t execute the JavaScript that’s often used in modern web visualizations. Using PhantomJS, I create a command-line script that can act like a web browser without me having to open up an actual browser.
The routine
Open browser.
Visit URL.
Activate screencapture program.
Highlight area of browser to capture.
Rename/move resulting screencapture image file.
wget isn’t good enough
Check out the rad graphics on the U.S. Department of Labor’s Data Enforcement homepage:
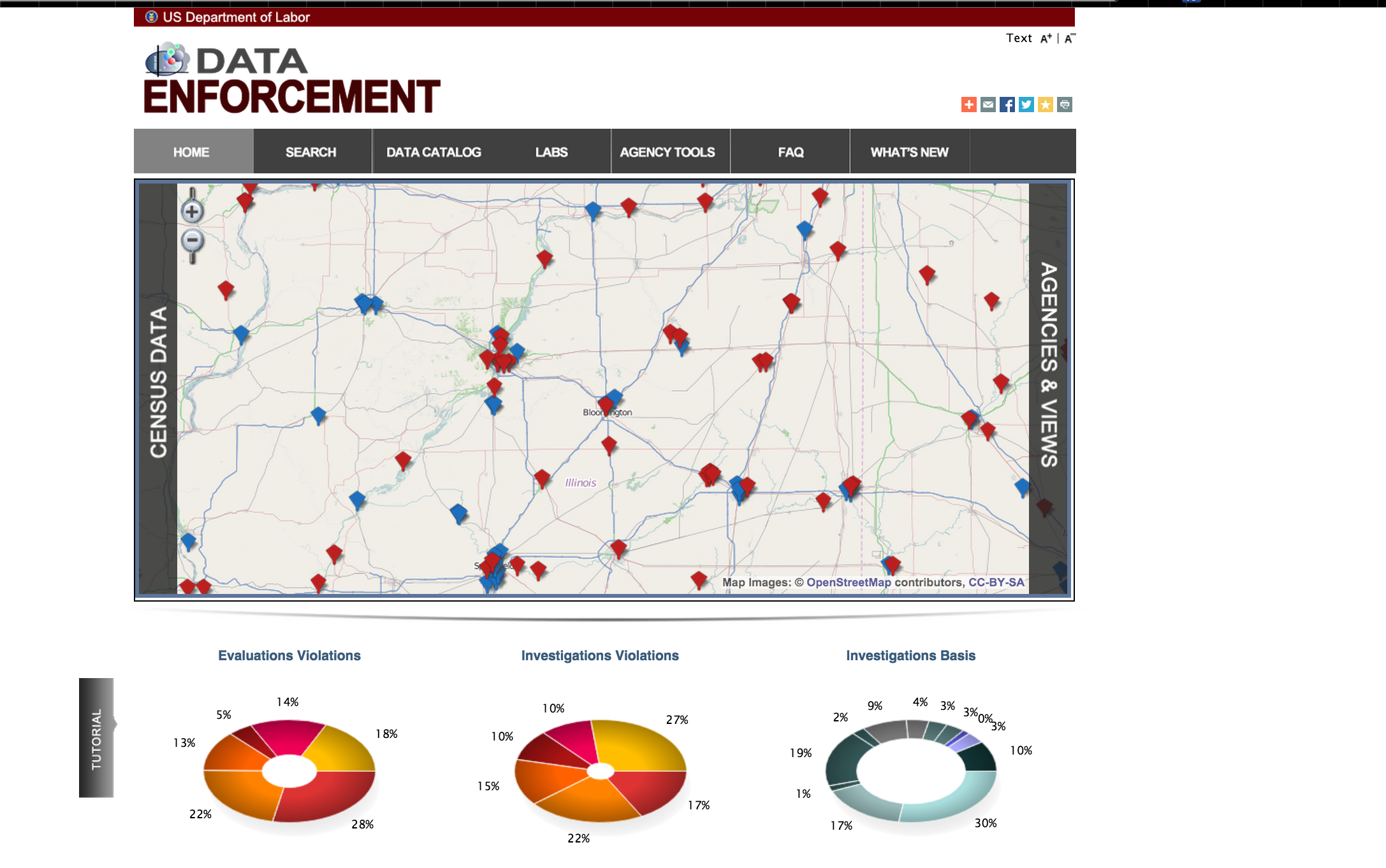
I’d like to archive that gem, along with a list of many other sites. But it’s a tedious pain to open each page and snapshot it. You might think that using wget would suffice. But the graphics on the Labor Dept. page are rendered dynamically via JavaScript. If you’re new to web development, this means there’s no direct URL to an image file.
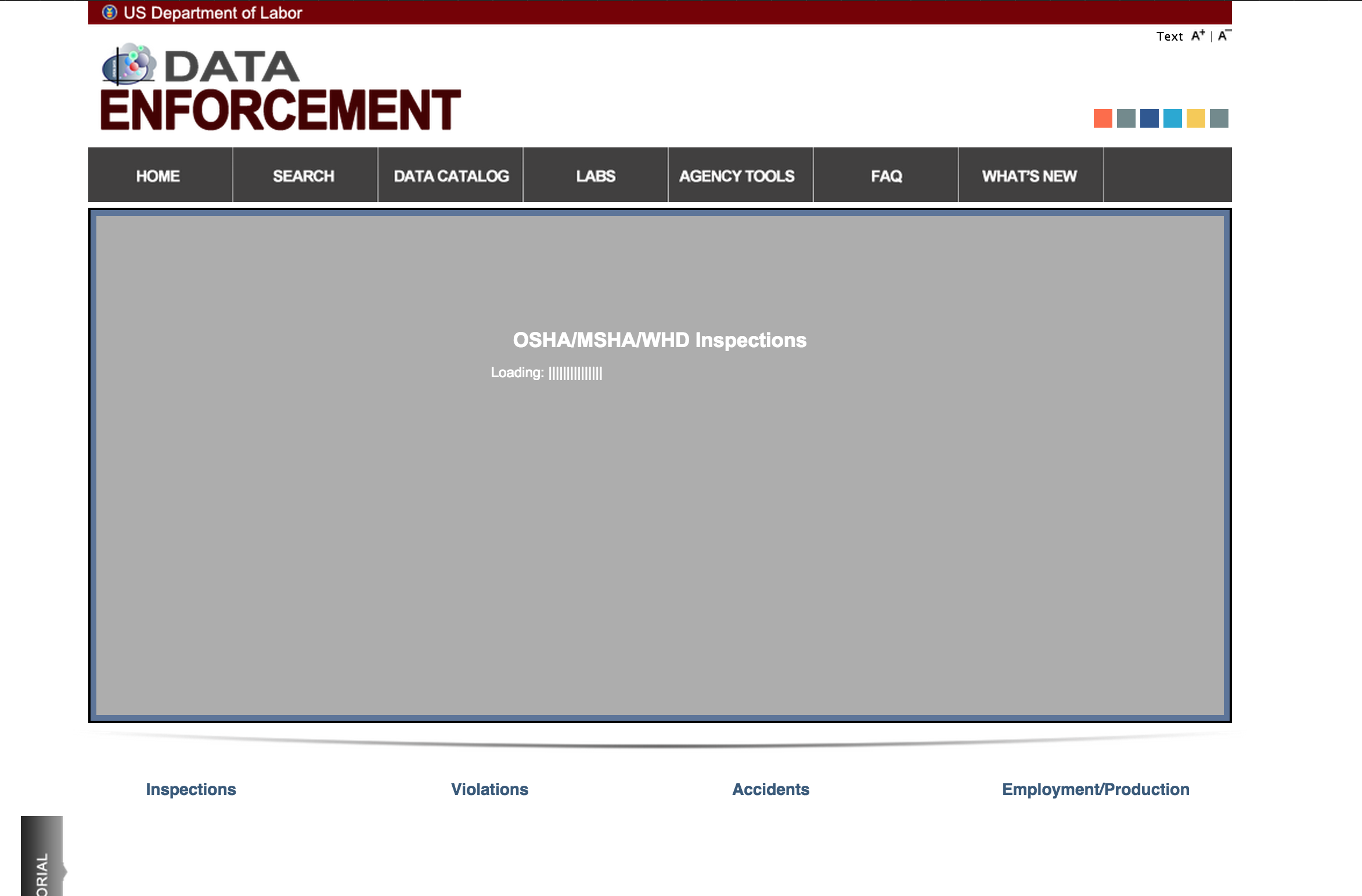
If you take a wget snapshot:
wget -E -H -k -K -nd -N -p\
-P /tmp/ogesdw \
http://ogesdw.dol.gov/homePage.php
You’ll find that the dynamic parts of the page don’t get mirrored:
Using the phantomscreencap.js command-line script:
phantomjs phantomscreencap.js http://ogesdw.dol.gov/homePage.php
We get a screenshot like this:
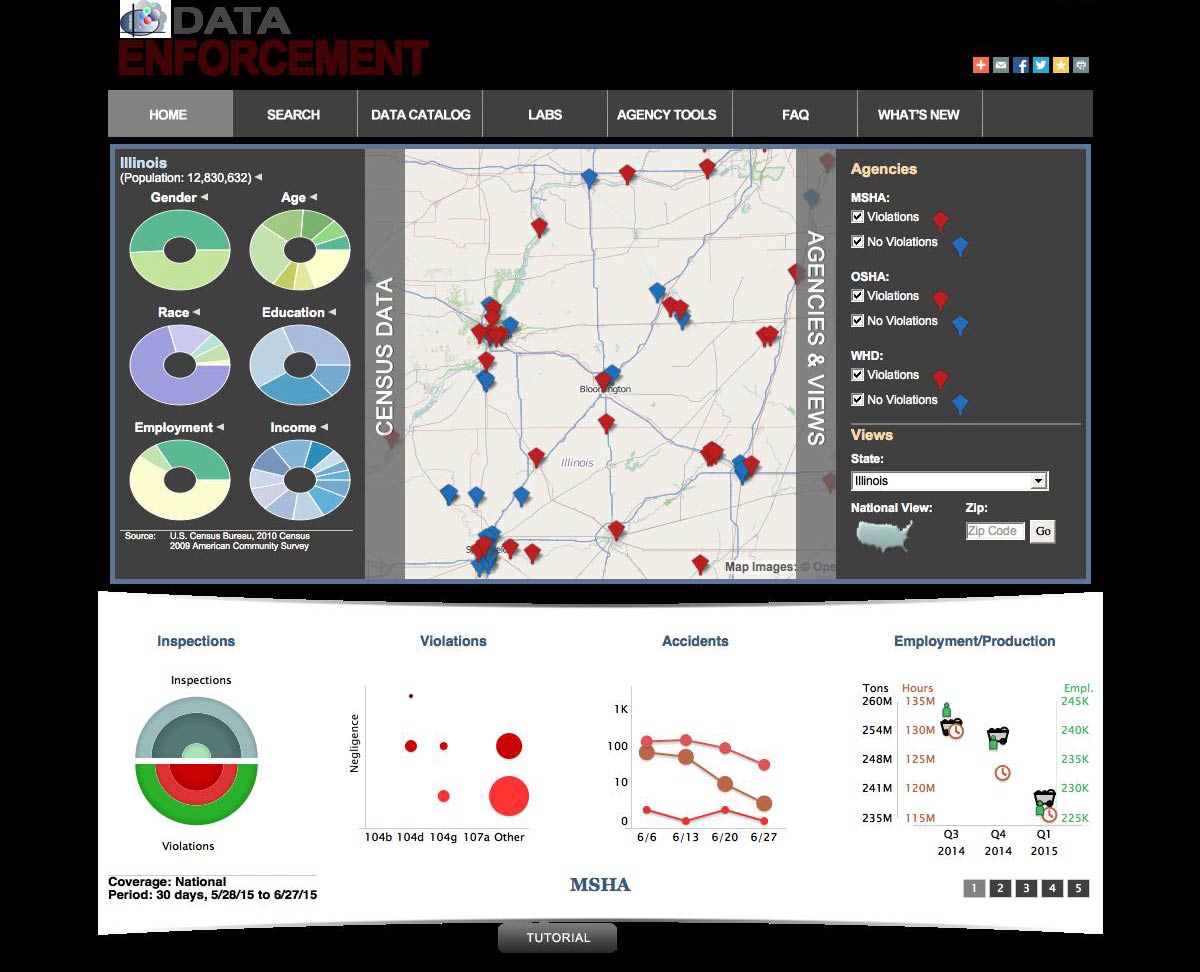
OK, that introduced a few other problems, but at least it rendered the JavaScript-powered visualizations.
Headless browsing with PhantomJS
PhantomJS is “is a headless WebKit scriptable with a JavaScript API.” For us, it means it’s a way to have programmatic access to a web browser. So instead of opening up a web browser, then visiting a webpage, just to see how long it takes to load (after everything is loaded and rendered), we can write a script to do all that webpage rendering, without opening up the web browser and clicking around. See more examples here.
So PhantomJS is great if you ever need to open a lot of web pages or access them in a bulk/batch fashion. The PastPages project, which archives news sites’ homepages, uses PhantomJS to take the snapshots.
Demonstration
Using phantomscreencap.js , the basic usage is:
phantomjs phantomscreencap.js http://www.example.com
Output:
Options:
{ url: 'http://www.example.com',
format: 'jpg',
output_filename: 'www_example_com.2015-07-04T190333.690Z.jpg',
quality: 75,
dim: { width: 1200, height: 900 } }
By default, the screenshot will be output to a timestamped filename based off of the URL, e.g. www_example_com.2015-07-04T190333.690Z.jpg
Problems
Basically, web stuff is a whole new world of complexity. And because PhantomJS isn’t, well, a full-service browser with hundreds of engineers working on it, its rendering of modern webpages will sometimes be significantly different than expected.
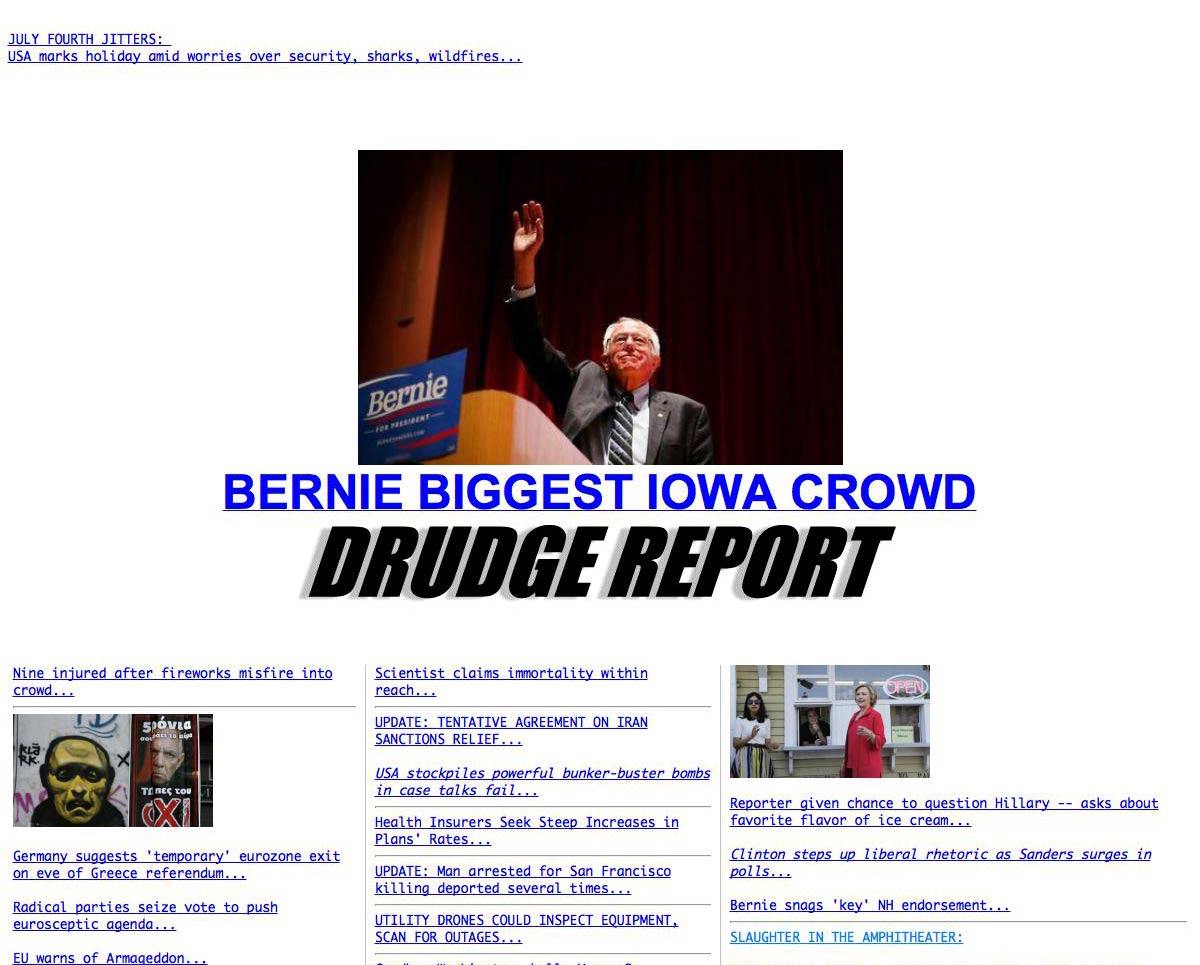
Can’t lock the viewport
Here’s part of the www.drudgereport.com snapshot; because of the complexities of web-rendering, my attempt to affix the viewport at 1200x900 pixels doesn’t quite work. So this is just a crop:
No fancy webfonts
Webfonts won’t be rendered, so sites with fancy fonts won’t appear exactly as intended. Here’s www.nytimes.com as seen by PhantomJS:
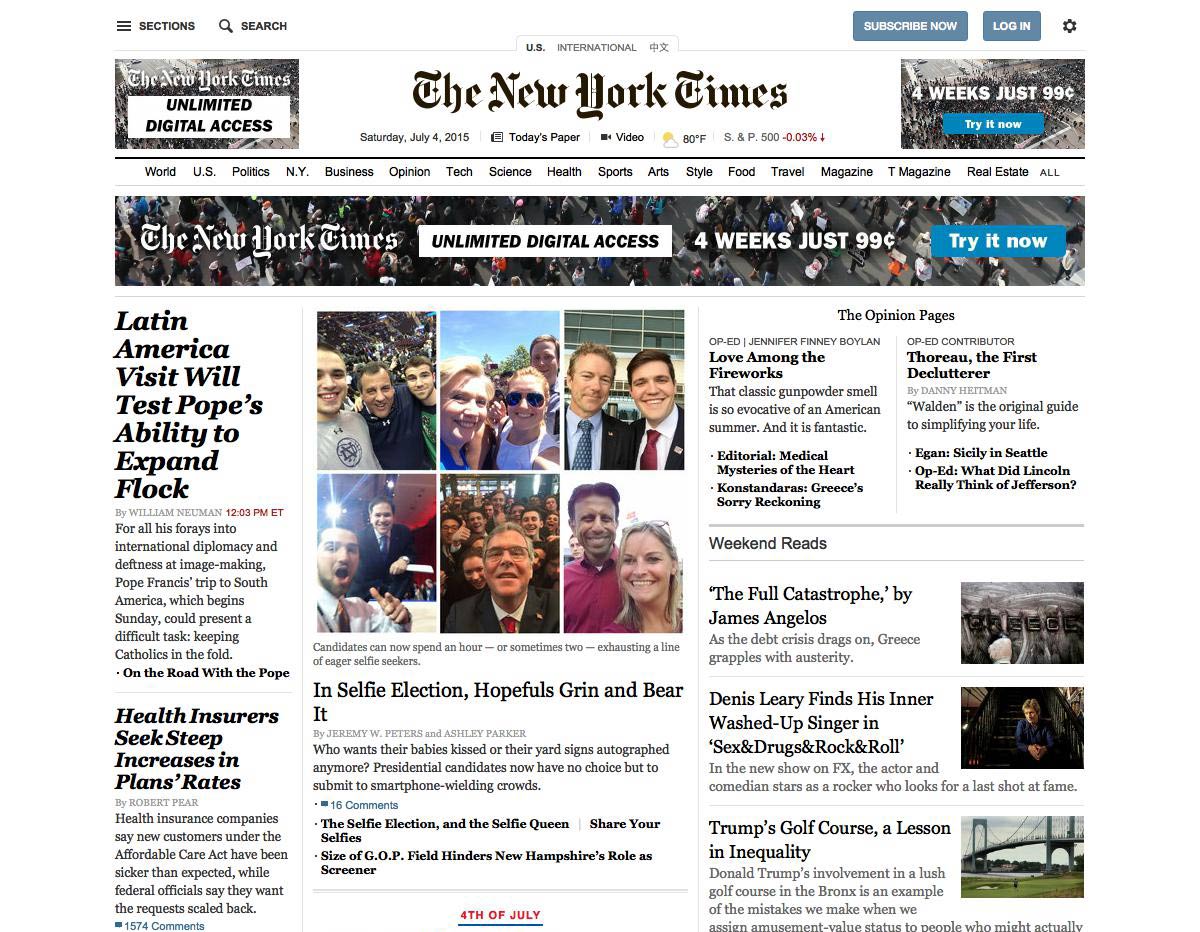
Here’s what www.nytimes.com is supposed to look like, with its web fonts rendered by the Google Chrome browser:

CasperJS
CasperJS is a framework that sits atop PhantomJS and is intended to make it easier to write automated visual testing, such as seeing what a site looks like across different device dimensions. I used it in the casper_capture.js example but it turns out to be more complicated than I needed. The killer problem for me was the trouble getting CasperJS to deal with HTTPS sites, which is the result of flaws in other parts of the web tech stack.