Prep
http://www.cde.ca.gov/ds/sp/ai/
public schools database
layout: http://www.cde.ca.gov/ds/si/ds/fspubschls.asp
landing: http://www.cde.ca.gov/ds/si/ds/pubschls.asp
direct link: ftp://ftp.cde.ca.gov/demo/schlname/pubschls.xls tsv: ftp://ftp.cde.ca.gov/demo/schlname/pubschls.txt
Downloading the Public Schools database
Good time to practice curl:
curl ftp://ftp.cde.ca.gov/demo/schlname/pubschls.xls \
-o /tmp/pubschls.xls
curl http://www.cde.ca.gov/ds/si/ps/documents/privateschools1415.xls \
-o /tmp/privateschools1415.xls
About xlrd
Data files
Basic operations
Open an Excel workbook with xlrd
from xlrd import open_workbook
book = open_workbook("/tmp/pubschls.xls")
Count the number of sheets
len(book.sheets())
# 1
Counting rows
sheet = book.sheets()[0]
sheet.nrows
# 17518
Accessing values by row
Using rows()
sheet.rows(0)
Using row_values()
sheet.row_values(0)
Displaying cells and columns
Printing school names
for i in range(sheet.nrows):
cols = sheet.row_values(i)
print(cols[6])
Spreadsheet cleaning
Before we can even get to the data cleaning, sometimes we have to do a bit of spreadsheet cleaning. This includes removing unnecessary boilerplate text that prevents the spreadsheet from being imported into a database or other formats.
A common issue is that the first three lines contain boilerplate information about the spreadsheet. These lines have to be manually removed before you can import into a database:
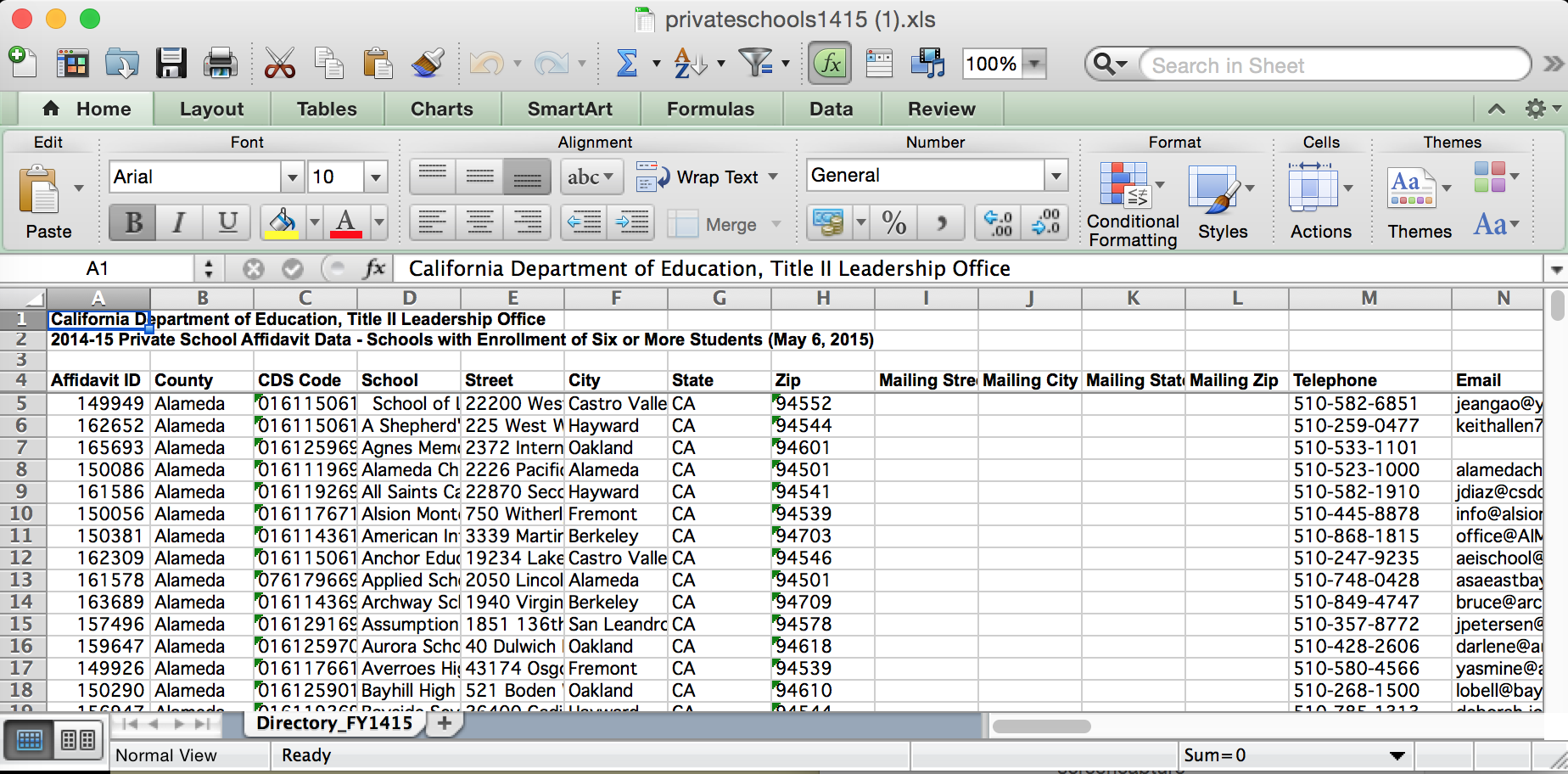
The first three lines in this spreadsheet have nothing to do with the data itself:

Removing them doesn’t seem like a big deal. But what if you have to import 5 spreadsheets? Or 50? Then that manual step can become a major hassle, among the other manual steps you might have to do.
Downloading the California private school directories
TK: The private school files can be found here.
To download just one of the files for this exercise:
curl http://www.cde.ca.gov/ds/si/ps/documents/privateschools1415.xls \
-o /tmp/privateschools1415.xls
To do it in Python:
import requests
resp = requests.get("http://www.cde.ca.gov/ds/si/ps/documents/privateschools1415.xls")
# download the file
# save it to /tmp/privateschools1415.xls
with open("/tmp/privateschools1415.xls", "wb") as f:
f.write(resp.content)
Clean boilerplate and convert to CSV
Let’s start with the 2014-2015 spreadsheet. In the snippet below, I include the code to download the file to the /tmp directory, just in case you didn’t use curl or wget as described above.
import csv
import xlrd
# Now open the local file with xlrd
book = xlrd.open_workbook("/tmp/privateschools1415.xls")
# Data is in the first sheet
sheet = book.sheets()[0]
# Now initialize the CSV file
csvname = "/tmp/privateschools1415.csv"
cf = open(csvname, "w")
cw = csv.writer(cf)
# The first 3 lines are skippable, so headers are on the 4th line
for r in range(3, sheet.nrows):
cw.writerow(sheet.row_values(r))
If you open the resulting CSV in Excel, you’ll see it loses the visual formatting and Excel-specific features, but keeps the structure:

Re-opening with Excel considered harmful
One of the “Excel-specific features” that is lost is the data type of each column. CSV is just plaintext. As a result, when you import a CSV file into Excel, Excel will try to take a guess at the data type of each column. For this particular spreadsheet, Excel believes that CDS Code is a really big number, hence, it changes the display of the column to scientific notation. A comparison of the XLS (on the left) and imported CSV sheets:
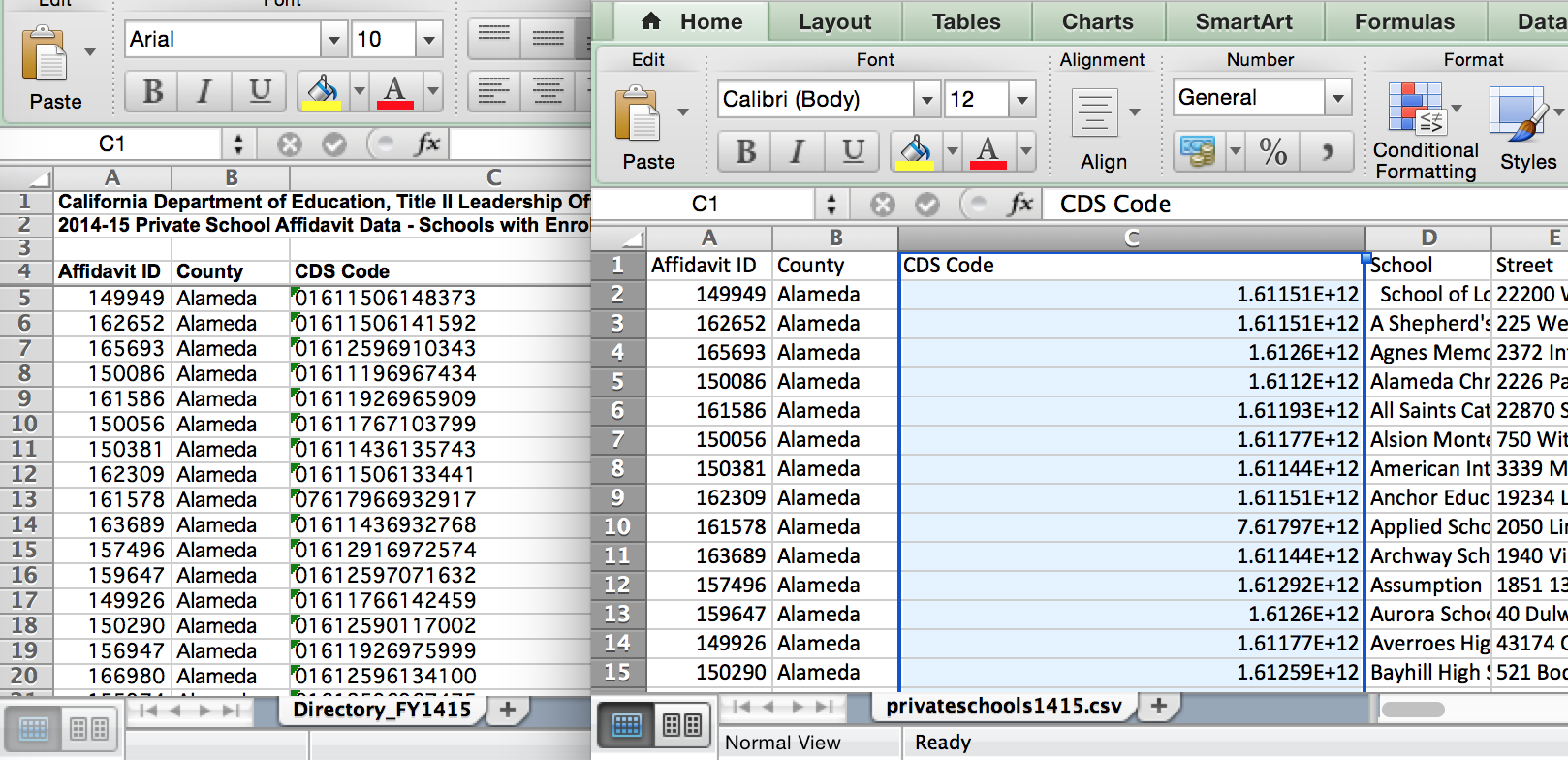
This auto-conversion of text-to-data-type is a sometimes/often convenient feature, but it can really bite you in the ass. If you’ve made the decision to move data from Excel into something else…you probably don’t want to re-open it in Excel. And this is another reason why it’s advantageous to programmatically do this kind of spreadsheet editing, as it’s very easy to forget all the point-and-click steps needed to make sure your data isn’t changed when Excel makes a “convenient” choice for you.
Batch spreadsheet cleaning
Assuming you have all the spreadsheets in:
To download them all with wget:
wget --recursive --level 1 --no-directories --accept xls \
-P /tmp/privschools
http://www.cde.ca.gov/ds/si/ps/
cd /tmp/privschools
Or you can download this zip file I’ve created.
The resulting file list in /tmp/privschools should look like this:
privat00.xls privat06.xls privateschools1112.xls
privat01.xls privat07.xls privateschools1213.xls
privat02.xls privat08.xls privateschools1314.xls
privat03.xls privat09.xls privateschools1415.xls
privat04.xls privat99.xls robots.txt
privat05.xls privateschools1011.xls
Do a row count
from glob import glob
import xlrd
for fname in glob("/tmp/privschools/*.xls"):
book = xlrd.open_workbook(fname)
sheet = book.sheets()[0]
print("%s rows in %s" % (sheet.nrows, fname))
Output:
4259 rows in /tmp/privschools/privat00.xls
4089 rows in /tmp/privschools/privat01.xls
3924 rows in /tmp/privschools/privat02.xls
3758 rows in /tmp/privschools/privat03.xls
3702 rows in /tmp/privschools/privat04.xls
3731 rows in /tmp/privschools/privat05.xls
3512 rows in /tmp/privschools/privat06.xls
3487 rows in /tmp/privschools/privat07.xls
3376 rows in /tmp/privschools/privat08.xls
3309 rows in /tmp/privschools/privat09.xls
4123 rows in /tmp/privschools/privat99.xls
3362 rows in /tmp/privschools/privateschools1011.xls
3160 rows in /tmp/privschools/privateschools1112.xls
3231 rows in /tmp/privschools/privateschools1213.xls
3273 rows in /tmp/privschools/privateschools1314.xls
3149 rows in /tmp/privschools/privateschools1415.xls
Show the headers
from glob import glob
import xlrd
for fname in glob("/tmp/privschools/*.xls"):
book = xlrd.open_workbook(fname)
sheet = book.sheets()[0]
print("%s columns in %s" % (len(sheet.row_values(3)), fname))
51 columns in /tmp/privschools/privat00.xls
51 columns in /tmp/privschools/privat01.xls
63 columns in /tmp/privschools/privat02.xls
58 columns in /tmp/privschools/privat03.xls
58 columns in /tmp/privschools/privat04.xls
58 columns in /tmp/privschools/privat05.xls
58 columns in /tmp/privschools/privat06.xls
61 columns in /tmp/privschools/privat07.xls
63 columns in /tmp/privschools/privat08.xls
63 columns in /tmp/privschools/privat09.xls
55 columns in /tmp/privschools/privat99.xls
68 columns in /tmp/privschools/privateschools1011.xls
74 columns in /tmp/privschools/privateschools1112.xls
63 columns in /tmp/privschools/privateschools1213.xls
63 columns in /tmp/privschools/privateschools1314.xls
63 columns in /tmp/privschools/privateschools1415.xls
Is all well? Not exactly:
from glob import glob
import xlrd
for fname in glob("/tmp/privschools/*.xls"):
book = xlrd.open_workbook(fname)
sheet = book.sheets()[0]
# show the first column
print("%s is first column in %s" % (str(sheet.row_values(3)[0]), fname))
Looks like the headers aren’t in the first column of each sheet
is first column in /tmp/privschools/privat00.xls
is first column in /tmp/privschools/privat01.xls
is first column in /tmp/privschools/privat02.xls
is first column in /tmp/privschools/privat03.xls
is first column in /tmp/privschools/privat04.xls
is first column in /tmp/privschools/privat05.xls
is first column in /tmp/privschools/privat06.xls
is first column in /tmp/privschools/privat07.xls
is first column in /tmp/privschools/privat08.xls
is first column in /tmp/privschools/privat09.xls
is first column in /tmp/privschools/privat99.xls
Affidavit ID is first column in /tmp/privschools/privateschools1011.xls
Affidavit ID is first column in /tmp/privschools/privateschools1112.xls
Affidavit ID is first column in /tmp/privschools/privateschools1213.xls
Affidavit ID is first column in /tmp/privschools/privateschools1314.xls
Affidavit ID is first column in /tmp/privschools/privateschools1415.xls
Open the file for 2007. You’ll see the position of the headers are different between pre-2010 files and post-2010 files:

And of course, to make things really complicated, the headers between every year is different. And the headers are sometimes split across different lines
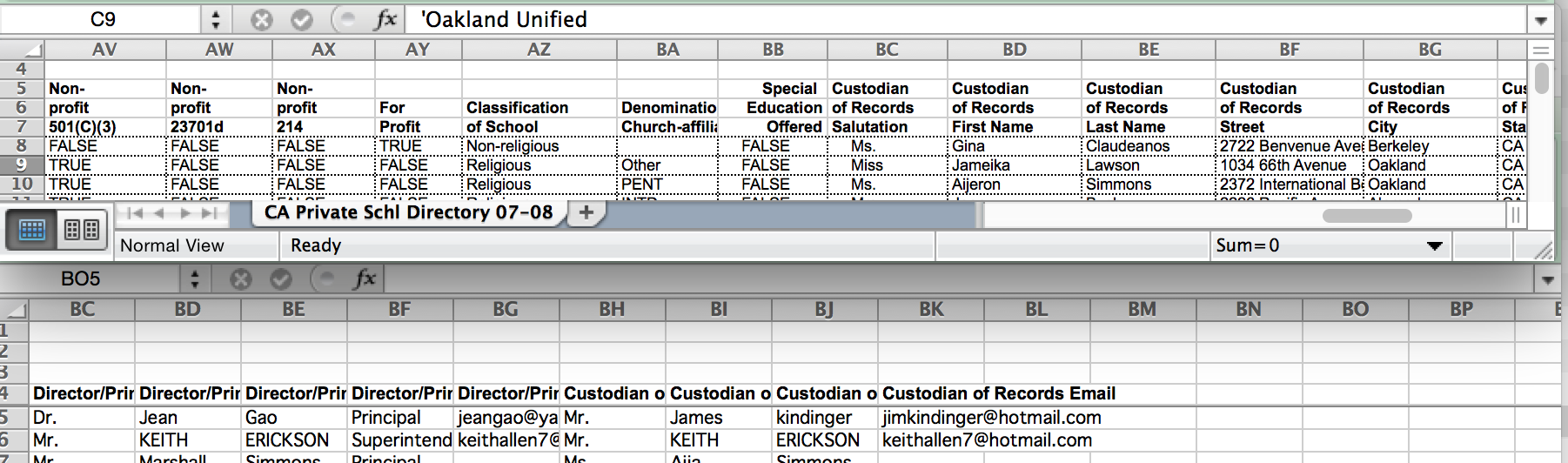
Have fun manually fixing those headers and importing them into a database!
Why, oh Lord, why?
You might ask yourself, Why does it have to be so complicated? The easy, likely answer is that they switched software vendors over the years. And/or the data specification was modified by whatever committee makes that decision. Either way, this is a real-world problem – ever-changing notions of what the data should be – that gets in the way of our hopes to unify the data.
But as far as programmatic spreadsheet cleaning goes, this one’s pretty easy. There are only two header formats.
The post-2010 headers are easy enough:
- Headers begin at the 4th line
- The first header is:
Affidavit ID - All headers are single-line
The pre-2010 headers follow this convention:
- Multi-line headers begin at the 5th line
- Headers end at the 7th line
- The first header is:
County
Header collation
Let’s work with just one file for now:
import xlrd
book = xlrd.open_workbook("/tmp/privschools/privat99.xls")
sheet = book.sheets()[0]
# ugly but it does the job:
headers = [[] for x in sheet.row_values(6)]
for y in [4, 5, 6]:
for x, val in enumerate(sheet.row_values(y)):
headers[x].append(str(val))
cleanheaders = [' '.join(h).strip() for h in headers]
print(cleanheaders)
Now we can fix all the files
from glob import glob
import xlrd
import csv
import re
for fname in glob("/tmp/privschools/*.xls"):
cname = fname + '.csv'
print("Creating", cname)
cf = open(cname, "w")
cw = csv.writer(cf)
book = xlrd.open_workbook(fname)
sheet = book.sheets()[0]
# test for post-2010 layout
if sheet.row_values(3)[0] == 'Affidavit ID':
for r in range(3, sheet.nrows):
cw.writerow(sheet.row_values(r))
else: # assume it is pre-2010 layout
# gather headers
headers = [[] for x in sheet.row_values(6)]
for y in [4, 5, 6]:
for x, val in enumerate(sheet.row_values(y)):
headers[x].append(str(val))
cleanheaders = [re.sub(r'\s+', ' ' , ' '.join(h).strip()) for h in headers]
cw.writerow(cleanheaders)
# write the rest of the data
for r in range(7, sheet.nrows):
cw.writerow(sheet.row_values(r))
Did it work?
I am far too lazy to check each file manually, so let’s just see if each file has the expected header needed to calculate total enrollment over time: