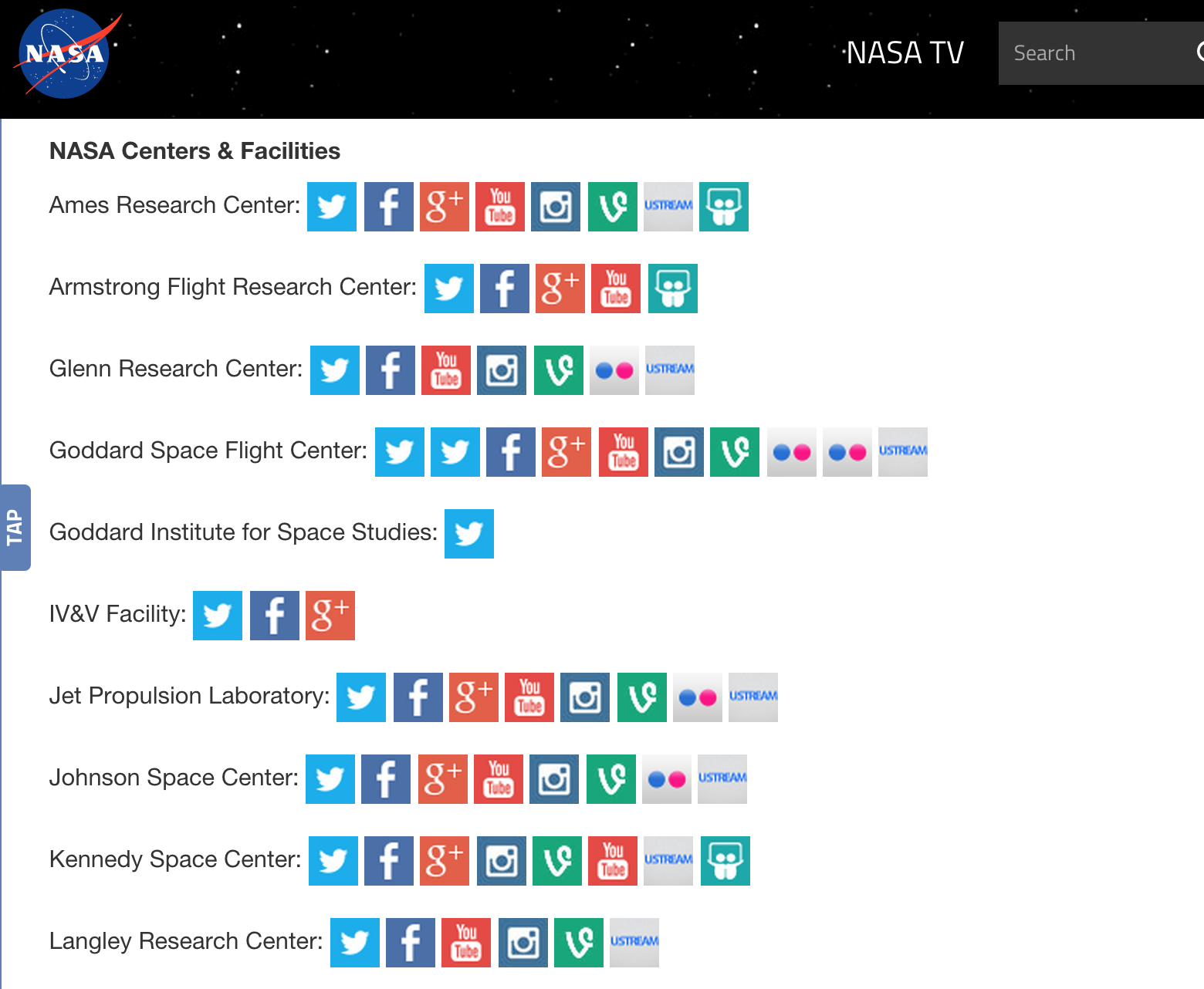
The use case
All Twitter account links have an obvious pattern, so use a regex (no HTML parsing needed!) to extract them, then one-by-one, use the Twitter API endpoint to execute a “follow” action.
The routine
Open and read webpage
Identify links to Twitter accounts
For each link, click to go to that Twitter account page
Click the “Follow” button
Example: Turn a webpage into a Twitter list
What is a Twitter account link?
Let’s start simple. For any given Twitter account, the URL looks like:
https://twitter.com/[SCREEN_NAME]
e.g.
What is a Twitter screen name
The “screen name” of a user, e.g. “WhiteHouse” for the user whose real name is The White House consists entirely of a combination of:
- Upper and/or lowercase English alphabet characters
- Numbers
- Underscore characters
Simple regex
The regex to capture that is pretty straightforward; for reasons that will be obvious later, I opt to use a capturing group rather than a positive-lookbehind:
import re
url = 'https://twitter.com/WhiteHouse'
m = re.search('https://twitter.com/(\w+)', url)
print(m.groups()[0])
# WhiteHouse
Using re.findall()
Given a block of text that contains any number of Twitter account URLs, intermixed with random text:
txt = """
Lorem ipsum dolor https://twitter.com/dancow sit amet, consectetur adipisicing elit. https://twitter.com/IRE_NICAR unde consequatur et, vel possimus https://twitter.com/geoffhing iure doloremque soluta https://twitter.com/srccon, adipisci nemo eligendi voluptates fugit dicta. Labore rem earum, architecto minima https://twitter.com/007
"""
We can use re.findall(), which returns “all non-overlapping matches of pattern in string, as a list of strings”:
matches = re.findall('https://twitter.com/(\w+)', txt)
for m in matches:
print(m)
# Result:
# dancow
# IRE_NICAR
# geoffhing
# srccon
# 007
Regex for HTML
What is HTML? Just text, including the hyperlinks. Which means that we don’t have to change a thing from what we used to match URLs and screennames from the arbitrary text in the previous example:
html = """
The President has a <a href="https://twitter.com/BarackObama">Twitter account</a> but he sometimes tweets from the <a href="https://twitter.com/WhiteHouse">White House's account</a>
"""
for m in re.findall('https://twitter.com/(\w+)', html):
print(m)
# BarackObama
# WhiteHouse
Variations in Twitter URLs
Unfortunately, Twitter account URLs are not all uniform. Here are the many variations of URLs that can point to the same account page:
http://twitter.com/ev
http://twitter.com/eve/
http://www.twitter.com/whitehouse
https://twitter.com/@dancow
https://www.twitter.com/007
https://www.twitter.com/@nytimes
//www.twitter.com/wsj
Here’s one possible regex that accounts for the above variations:
//(?:www\.)?twitter.com/@?(\w+)/?["\']
In action:
import re
urls = """
http://twitter.com/ev
http://twitter.com/eve/
http://www.twitter.com/whitehouse
https://twitter.com/@dancow
https://www.twitter.com/007
https://www.twitter.com/@nytimes
//www.twitter.com/wsj
"""
rx = r'//(?:www\.)?twitter.com/@?(\w+)/?'
for m in re.findall(rx, urls):
print(m)
# ev
# eve
# whitehouse
# dancow
# 007
# nytimes
# wsj
URLs extracted from the Follow buttons
And there are also Twitter “web intents” – i.e. Follow buttons – that point to accounts that we probably want to capture:
<a id="follow-button" class="btn" title="Follow @dancow on Twitter" href="https://twitter.com/intent/follow?original_referer=http%3A%2F%2Fdanwin.com%2F2013%2F11%2Flonnie-johnson-the-millionaire-super-soaker-inventing-rocket-scientist%2F&region=follow_link&screen_name=dancow&tw_p=followbutton"><i></i><span class="label" id="l">Follow <b>@dancow</b></span></a>
The relevant URL:
https://twitter.com/intent/follow?original_referer=http%3A%2F%2Fdanwin.com%2F2013%2F11%2Flonnie-johnson-the-millionaire-super-soaker-inventing-rocket-scientist%2F&region=follow_link&screen_name=dancow
For this situation, it’s easier just to use a separate regex than to come up with an omni-pattern:
rxintent = r"twitter.com/intent/follow\?.+?creen_name=(\w+)"
linktxt = '<a href="https://twitter.com/intent/follow?original_referer=http%3A%2F%2Fdanwin.com%2F2013%2F11%2Flonnie-johnson-the-millionaire-super-soaker-inventing-rocket-scientist%2F&region=follow_link&screen_name=dancow">button</a>'
print(re.search(rxintent, linktxt).groups()[0])
# dancow
Filter out duplicates
Twitter URLs to exclude
This is problematic:
https://twitter.com/intent/follow
TK exclude
Exercise: Follow all NASA accounts